Why KServe?
The open-source standard for self-hosted AI, providing a unified platform for both Generative and Predictive AI inference on Kubernetes.Simple enough for quick deployments, yet powerful enough for the most demanding enterprise workloads.
🤖 Generative AI
🧮Optimized Backends
vLLM and llm-d for high-performance LLM serving
📌OpenAI Compatible
Drop-in OpenAI protocol for seamless LLM integration
🚅GPU Acceleration
High-performance serving with optimized GPU memory management
💾Model Caching
Reduce load times and improve latency for frequently used models
🗂️KV Cache Offloading
Offload KV cache to CPU/disk for longer sequence handling
📈Autoscaling
Request-based autoscaling tuned for generative workloads
🔧Hugging Face Ready
Native HuggingFace model support with streamlined deployment
📊 Predictive AI
🧮Multi-Framework
TensorFlow, PyTorch, scikit-learn, XGBoost, ONNX, and more
🔀Intelligent Routing
Seamless routing between predictor, transformer, and explainer
🔄Advanced Deployments
Canary rollouts, pipelines, and ensembles with InferenceGraph
⚡Auto-scaling
Scale-to-zero for predictive workloads on any autoscaler
🔍Model Explainability
Built-in feature attribution to understand prediction reasoning
📊Advanced Monitoring
Payload logging, outlier, adversarial, and drift detection
💰Cost Efficient
Scale-to-zero on expensive resources when not in use
Simple and Powerful API
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features to your ML deployments.
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "llm-service"
spec:
predictor:
model:
modelFormat:
name: huggingface
resources:
limits:
cpu: "6"
memory: 24Gi
nvidia.com/gpu: "1"
storageUri: "hf://meta-llama/Llama-3.1-8B-Instruct"
How KServe Works
KServe provides a Kubernetes custom resource definition for serving ML models on arbitrary frameworks, encapsulating complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features to your ML deployments.
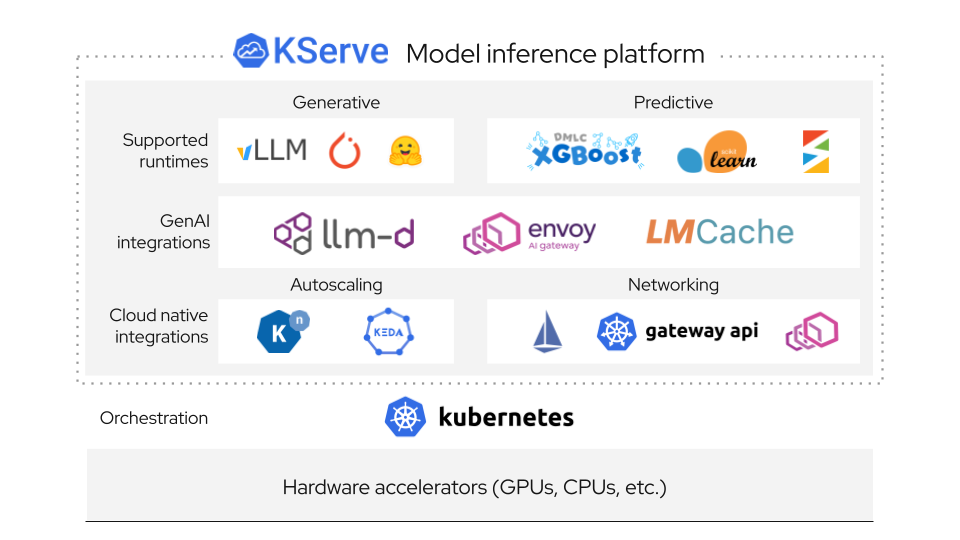
Control Plane
Manages lifecycle of ML models, providing model revision tracking, canary rollouts, and A/B testing
Data Plane
Standardized inference protocol for model servers with request/response APIs, supporting both predictive and generative models
InferenceService
Core Kubernetes custom resource that simplifies ML model deployment with automatic scaling, networking, and health checks
Inference Graph
Enables advanced deployments with pipelines for pre/post processing, ensembles, and multi-model workflows
Quick Start
Get started with KServe in minutes. Follow these simple steps to deploy your first model.
Install KServe
Install KServe and its dependencies on your Kubernetes cluster:
kubectl apply -f https://github.com/kserve/kserve/releases/download/v0.11.0/kserve.yaml
Create an InferenceService
Deploy a pre-trained model with a simple YAML configuration:
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "qwen-llm"
spec:
predictor:
model:
modelFormat:
name: huggingface
storageUri: "hf://Qwen/Qwen2.5-0.5B-Instruct"
resources:
requests:
cpu: "1"
memory: 4Gi
nvidia.com/gpu: "1"
Send Inference Requests
Make predictions using the deployed model:
curl -v -H "Host: qwen-llm.default.example.com" \
http://localhost:8080/openai/v1/chat/completions -d @./prompt.json
Trusted by Industry Leaders
KServe is used in production by organizations across various industries, providing reliable model inference at scale.







Ready to Transform Your ML Deployment?
Simplify your journey from model development to production with KServe's standardized inference platform for both predictive and generative AI models